
PricingStrategie
Best Practice Teil 1: Produkteinführung beim Medizintechnik-Unternehmen XMed Unser Kunde, nennen wir ihn zur Vereinfachung XMed, ist ein...
Der Verkauf von Ersatzteilen ist für Hersteller im Maschinenbau eine lukrative Einnahmequelle. Die mit Ersatzteilen erzielbaren Margen sind meist höher als im Primärgeschäft. Die aus Kundensicht relativ hohen Preise führen allerdings dazu, dass sich am Markt immer mehr Anbieter etablieren, die den Kunden günstigere Nachbauten der Original-Ersatzteilen anbieten. Um diesem Trend entgegen zu wirken müssen Hersteller zunächst verstehen, welche Kunden in welchen Warengruppen preissensibel agieren. Maschinelles Lernen bietet fortschrittliche Techniken, um preissensible Kunden und Warengruppen zu identifizieren.
 Ein Kunde, der für eine Maschine unerwartet ein Ersatzteil benötigt, ist in einer anderen Kaufsituation als ein Maschinen-Neukäufer. Der oft zeitkritische Bedarf für ein spezielles Teil reduziert die Preissensibilität – die Kunden sind meist bereit, relativ hohe Preise zu bezahlen, insbesondere wenn das benötigte Teil schnell beschafft werden kann.
Ein Kunde, der für eine Maschine unerwartet ein Ersatzteil benötigt, ist in einer anderen Kaufsituation als ein Maschinen-Neukäufer. Der oft zeitkritische Bedarf für ein spezielles Teil reduziert die Preissensibilität – die Kunden sind meist bereit, relativ hohe Preise zu bezahlen, insbesondere wenn das benötigte Teil schnell beschafft werden kann.
Bei bestimmten Teilen ist aber ein Austausch nach einer gewissen Betriebszeit absehbar. Verschleißteile und Ersatzteile, die bei Wartungen regelmäßig gewechselt werden müssen, erhöhen spürbar die operativen Betriebskosten der Maschinen des Kunden. Diese Teile sind für eine professionellen Einkaufsabteilung gleichermaßen interessant wie für viele unabhängige Hersteller, die diese nachbauen und im Markt anbieten können.
Viele Maschinen-Ersatzteile sind zudem ursprünglich Kaufteile von Zulieferern ohne exklusive Lieferbeziehung. Der Einkauf einiger Kunden nutzt diese Anbieter gerne als alternative Bezugsquelle. Meist sind es einige wenige, aber bedeutende Zulieferer, die mit eigenen Vertrieb am Markt arbeiten, bei denen dies zu beobachten ist.
Eine weitere Quelle für relativ günstige Ersatzteile ist die Refabrikation (engl. Remanufacturing). Diese wird oft von den Herstellern selbst angeboten, es gibt aber auch unabhängige ET-Kreisläufe von Drittanbietern, die gebrauchte Ersatzteile kaufen, aufbereiten und wiederverkaufen. Im Werkzeugmaschinenbau ist dies z.B. bei Motorspindeln zu beobachten, wo sich praktisch ein Independent Aftermarket wie in der Automobilindustrie für wiederaufbereitete Spindeln etabliert hat.
Ersatzteil-Kunden sind selten „illoyal“ in allen denkbaren Warengruppen. Besonders gefährdet sind – wie oben erläutert – hochfrequente Ersatzteile, die entweder Verschleiß- oder Serviceteile sind und alle Teile, die von nicht-exklusiven Zulieferern stammen. Für viele Warengruppen kann man annehmen, dass der Kunde die Verfügbarkeit und Qualität von kritischen Ersatzteilen einer nur moderaten Ersparnis vorziehen wird. Erst wenn sich bei Ersatzteilen eine deutliche Reduktion von Kosten realisieren lässt, oder die Teile in größeren Stückzahlen benötigt werden, muss allgemein von einer Gefahr der Piraterie bzw. unabhängigen Ersatzteilbeschaffung ausgegangen werden.
Maschinelles Lernen ist der Teil der Künstlichen Intelligenz, in der Maschinen aus Erfahrungen Wissen generieren sollen. Im Maschinellen Lernen werden keine expliziten Regeln verwendet, sondern Wissen direkt aus den Daten generiert.
Ein bekanntes Anwendungsgebiet für Maschinelles Lernen sind Empfehlungssysteme. Streamingdienste wie etwa Netflix oder Spotify schlagen ihren Kunden selbständig „passende“ Filme bzw. Musik vor. Bemerkenswert dabei ist, dass die verwendeten Verfahren meist keine expliziten, manuell gepflegten inhaltlichen Beziehungen der Medien untereinander verwenden (z.B. Kategorien wie „Action“ bzw. „Liebeskomödie“, Musikrichtungen oder auch bestimmte Schauspieler), sondern die Empfehlungen vollständig aus den Gewohnheiten der Nutzer ableiten können. Man spricht hierbei von kollaborativem Filtern. Die Algorithmen verallgemeinern zunächst die Seh- bzw. Hörgewohnheiten hunderttausender von Kunden und können dann für jeden Nutzer des Streamingdienstes die wahrscheinlichsten passenden Angebote auf der Basis seines bisherigen Verhaltens ableiten.
Im Jahr 2006 schrieb Netflix einen Preis aus, um den von ihnen verwendeten Algorithmus für Filmempfehlungen zu verbessern. Nach drei Jahren wurde das Preisgeld von einer Million Dollar dem „Bellkor’s Pragmatik Chaos“ Team zugeschrieben, dessen Verfahren das Alte um mehr als 10% verbessern konnte. Die Datenbasis der Aufgabenstellung sind die expliziten Bewertungen, die Filme von Nutzern von Netflix geben – die jeweils eins bis fünf „Sterne“, mit denen Nutzer Filme bewerten können.
Das Kaufverhalten bei Ersatzteilen kann als Datengrundlage eines derartigen kollaborativen Filterns verwendet werden. Genauso wie das Betrachten bestimmter Filme Rückschlüsse auf die Vorlieben eines Netflix-Kunden erlauben, so kann das Kaufverhalten in Ersatzteil-Warengruppen verwendet werden, den üblichen Bedarf in jeweils anderen zumindest grob abzuschätzen. Liegen die Käufe eines Kunden stark unterhalb dessen, was man aufgrund des gelernten Erfahrungswissens erwarten könnte, so kann dies ein Indiz für alternative Beschaffung sein – der Kunde agiert in diesen Warengruppen vermutlich illoyal.
Maschinenbauer haben oft zehntausende von Kunden und hunderte von ET-Warengruppen. Die Zahl der jedes Jahr verkauften Ersatzteile liegt meist im mittleren fünfstelligen Bereich. Eine manuelle Analyse aller Verkaufsdaten für jeden Kunden wäre daher sehr aufwändig. Durch geeignete Verfahren aus dem maschinellen Lernen kann eine Loyalitätsanalyse jedoch enorm vereinfacht werden. Die Maschinenbauer können solche Analysen verwenden, um z.B. Preise in stark gefährdeten Warengruppen anzupassen oder durch aktive Preismaßnahmen bei preissensiblen Kunden verlorene Marktanteile zurückzugewinnen.
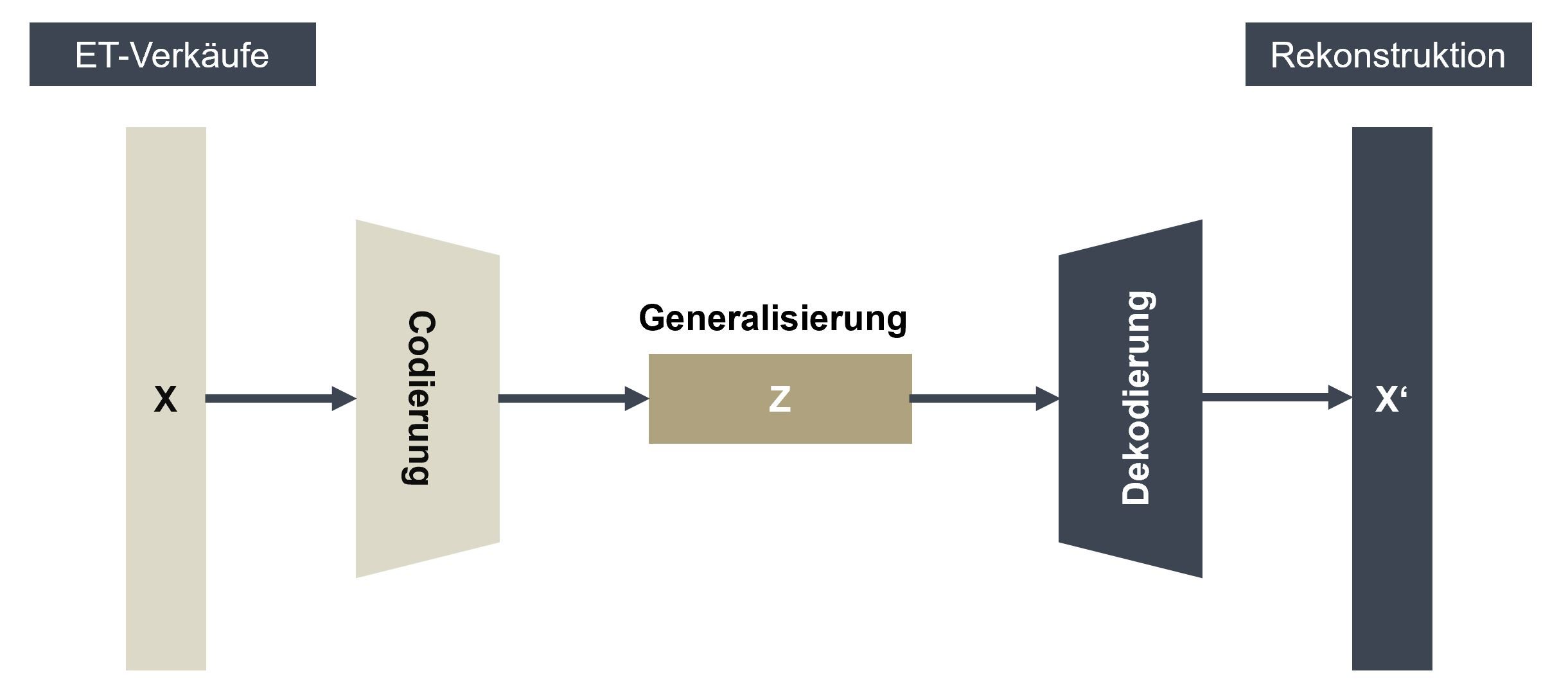
Das von Netflix verwendete Lernverfahren basiert auf Dimensionsreduktion. Die detaillierten Daten von Kunden werden dabei in eine vereinfachte Repräsentation umgerechnet, welche die latenten (verdeckten) Beziehungen der Filmbewertungen verallgemeinert. Diese generalisierende Repräsentation ist bewusst nicht in der Lage, alle Sehgewohnheiten der Netflix-Kunden exakt abzubilden, sondern stellt diese mathematisch lediglich als Annäherungen dar. Durch Rückprojektion dieses verallgemeinerten Erfahrungswissens auf die jeweiligen Nutzer kann abgeschätzt werden, welche Filme dieser wie bewerten würde, wenn er sie ansehen würde.
In ähnlicher Weise kann auch das Kaufverhalten vieler Kunden beim Kauf von Ersatzteilen verallgemeinert und genutzt werden. Im Gegensatz zu Filmbewertungen soll hierbei für jeden Kunden abgeschätzt werden, welchen Umsatz dieser pro Warengruppe „normalerweise“ in einem gegebenen Zeitraum machen müsste. Die bekannten Daten aller Kunden bilden die Basis eines komplexen, gelernten Vorhersagemodells. Durch Anwendung dieses Modells auf das jeweilige tatsächliche Kaufverhalten lassen sich Warengruppen identifizieren, in denen der Umsatz höher als der beobachtete sein müsste – dies ist der gesuchte Hinweis auf möglicherweise verlorene Marktanteile.
Sinnvoll ist im Ersatzteilgeschäft eine Einschränkung der verwendeten Daten auf Warengruppen, in denen überhaupt alternative Bezugsquellen existieren könnten – bzw. auf Lieferanten und Teile, bei denen keine Exklusivität angenommen werden kann.
Die obige Abbildung veranschaulicht das Vorgehen des Lernalgorithmus. Ziel ist eine Rekonstruktion der Verkaufsdaten für jeden Kunden aus einer gelernten Generalisierung des Verhaltens vieler Kunden. Die Repräsentation Z wird so gewählt, dass nicht alle Details der ursprünglichen Daten gelernt werden können. Die Abweichungen der dann notwendigerweise „fehlerhaften“ Rekonstruktion der Ausgangsdaten gibt deutliche Hinweise auf illoyale Kunden und mögliche Potentiale in den Warengruppen.
Im Rahmen eines Beratungsprojektes für einen führenden Maschinenbauer soll ermittelt werden, welche Warengruppen sich für eine durch aktuelle Kostensteigerung notwendige Preiserhöhung eignen. Der Maschinenbauer hat erkannt, dass sich Kunden vermehrt bei anderen Quellen nach günstigen Alternativen umsehen. Die Preissteigerung soll daher weniger stark in den Warengruppen erfolgen, wo heute bereits ein Verlust von Marktanteilen erfolgt ist.
Datengrundlage der Analyse waren ET-Bestellungen mehrerer Jahre von Kunden einer Region. Von diesen Bestellungen wiederum wurden Warengruppen ausgewählt, die einen Mindestumsatz pro Jahr pro Kunde erreichen. Ausgeschlossen wurden Bestellungen von Normteilen und Penny-Parts. Diese sind zwar normalerweise gute Kandidaten für Fremdbeschaffung, der Maschinenbauer setzt hier aber bereits stark auf marktorientiertes Pricing. Letztendlich ergab dies eine Datenmenge von ca. 11.000 Datenpunkten aus Kunden und Warengruppen.
Implementiert wurde das Lernverfahren von R&P als Python-Anwendung mit einer Datenvisualisierung in Power BI. Da die Datenmenge in diesem Fall vergleichsweise klein war (Netflix betrachtet für Filmbewertungen Hunderte von Millionen von Datenpunkten!) konnten wir für die Loyalitätsanalyse rechnerisch sehr aufwändige Verfahren anwenden.
Die aus der oben beschriebene modellhafte Vorhersage erlaubt es, pro Kunden Potentiale in jeder Warengruppe zu ermitteln. Liegt dieses Potential deutlich höher als das tatsächlich beobachtete Bestellverhalten, so kann dies ein Hinweis auf illoyales Kaufverhalten sein – es kann aber auch bedeuten, dass der Kunde seine Maschinen anders nutzt als andere Kunden und daher andere Verschleißteile in anderen Mengen benötigt. Für die von uns untersuchte Fragestellung war der einzelne Kunde hier allerdings zunächst unerheblich – interessant waren lediglich die aggregierten Potentiale der Warengruppen als Indikatoren für eine bestehende Preissensibilität vieler Kunden.
Durch vertiefende Expertengespräche konnten wir klären, dass viele der von uns automatisch identifizierten Warengruppen tatsächlich ein erhebliches Potential für „Piraterie“ bieten. Im Gegensatz zum Bauchgefühl der Experten quantifiziert unsere Analyse, wie hoch das Potential bzw. die Preissensibilität in den Warengruppen ungefähr ist. Die besonders gefährdeten Warengruppen werden im Rahmen der Preiserhöhung nun wesentlich konservativer im Preis erhöht, als dies ursprünglich geplant war.
Die hier vorgestellte, beispielhafte Anwendung von Maschinellen Lernverfahren ist nur ein Beispiel für das Potential, das die Anwendung von Künstlicher Intelligenz im Ersatzteil-Preismanagement besitzt. Die systematische Anwendung dieser neuartigen Methoden erlaubt ein differenzierteres Vorgehen bei Preisanpassungen und kann in Zukunft auch die analytische Basis eines deutlich aktiveren Ersatzteilvertriebs bilden.


